Dependency management at scale
This is part 2 of a series of posts documenting my attempts at understanding and writing software to support dependency management. In order to limit the scope, the first problem I wanted to solve is keeping Java module dependencies up to date. In previous post I introduced the problem and gave a bit of background on the way versioned jar dependencies work. In this post, we will explore the a real versioned module ecosystem and come up with a way to keep it up to date.
Jez Humble's Continuous Delivery book discusses dependency management on a simple example.

The example I got to work with, is the graph of versioned Java libraries at my company, which looks like this:
 In the above graph, red edges indicate out of date, stale, dependencies, red circles indicate modules which do not build (due to failing tests or other reasons), and blue edges indicate presence of a cycle. As you can see, at scale, the dependency integration presents a new set of challenges.
In the above graph, red edges indicate out of date, stale, dependencies, red circles indicate modules which do not build (due to failing tests or other reasons), and blue edges indicate presence of a cycle. As you can see, at scale, the dependency integration presents a new set of challenges.
Given a module ecosystem like the one above, is not possible to successfully update all dependencies in one pass. The modules whose builds are failing cannot be updated automatically, and they block any propagation of updates up the graph. Additionally, we can expect some updates to be incompatible, and cause more failures in upstream modules. Last, but not least, some critical issues may not be caught by the tests until much higher levels on the graph are reached, leading to entire subtrees being unreleasable and affecting release schedule of applications that depend on them.
Since it's not apparent to human eye that a small batch of version updates has improved the staleness of the graph, a staleness metric is necessary to show and chart progress. Additionally, from studying this metric over time, we can determine how it normally grows, and what is the happy spot for this ecosystem once we begin to reduce the staleness.
Naive metric
On the first attempt, one may construct a metric that simply measures the number of stale edges on the graph. The lower the number, the better (more integrated) the modules would be. However, there is a problem with this approach. Consider a simple case with one out of date dependency at the bottom rank of the graph (outdated dependency in red).

The initial staleness metric value is 1. Once we update this dependency, we need to publish a new artifact with updated dependency, and we find that the 3 downstream projects are now outdated. The value of the metric is 3.

So even though we reduced the staleness in the graph, the naive staleness metric just went up. Eventually, we would complete the integration, leaving all edges up to date, but keep in mind that we are operating in the environment where complete integration isn't possible and may not even be desirable. So a staleness metric we use needs to account accurately for partial improvements. Any update of a dependency in the graph should result in staleness metric reduction.
A better metric
A better metric simply takes into account the flaw described in previous metric - total cost of integration. In order to compute the value, we must know a position of a module in the graph, and consider all the steps necessary for complete integration. We take one stale dependency at a time and enumerate all the steps it would take to completely integrate that change. In other words, we count the number of edges in the spanning tree rooted at the module whose stale dependency is being updated. So, in the first picture above, the staleness metric would be 4, and after updating the first direct dependency, it would be 3. To get a better feel, let's look at some more complicated examples.
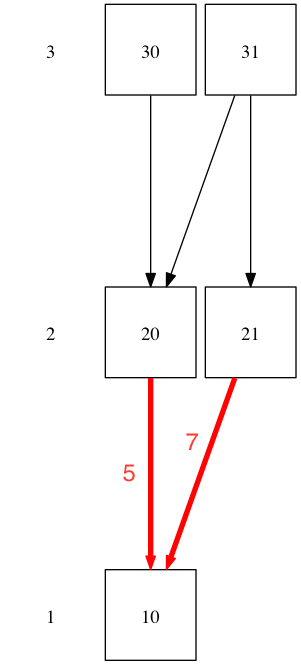
In the example below, there are two modules that have outdated dependencies. We are also beginning to address modules by name, which is determined by their rank in the graph and position within that rank.

Keep in mind that integration may fail, so we need to consider each of the outdated edges separately. We first calculate the dependency staleness for module "20", which is 3 (10, 20, 30, 31). We then calculate staleness for module 21, which is 2 (10, 21, 31). So the total staleness value is 5.
From this diamond dependency, a special case arises if diamond dependencies are present downstream. In the graph below, once we begin integration, module 20 is out of date, and by the same logic as we used above, the dependency between 40 and 50 should be counted twice, once when integration is coming from the left, once when it's coming from the right.

However, for the little value that it adds in some edge cases, this requirement adds too much complexity to calculating the metric, so I arbitrarily choose to ignore diamond dependencies if they are not directly involved in the stale edge that's being calculated. Therefore staleness metric for the graph in this example is 6 (and not 7).
We introduce versions
So far we considered the staleness of a single dependency staleness as binary - it's either stale or not. But to accurately reflect reality we need to take into account how many versions behind the given dependency is. The underlying principle is that the metric needs to take into account the smallest reductions in staleness, even if integration with the latest version isn't possible. Therefore, in calculating staleness, we should pretend that we're integrating each version separately. In practice, the calculation can be accomplished by multiplying the metric calculated for a stale edge by number of versions that that edge is behind. Consider the example below, where one dependency is 5 versions behind, and the other 7:

The staleness metric in the above example is 29 (3 x 5 + 2 x 7).
Next issue to consider, once we start looking at the past is that the dependency graph changes over time. (There's a visual example in the previous post.) For this metric, I propose to only consider the most recent version of the graph. There are two reasons for that - one is simplicity of computing the metric, another is that I don't want old dependencies unnecessarily weighing in on the staleness.
To better understand this latter reason, consider an extreme case of a jar which still has some old versions of other jars depend on it, but which no current version depends on. If we tried to improve the metric directly, we'd check out downstream modules, only to find out they no longer depend on the jar - so there would be nothing to do. Since we ignore past versions of the dependency graph, this jar's contribution to staleness metric is 0, and whoever is trying to improve the metric will not waste time trying to update a version of that jar.
At the end of this section, one final example, of multiple stale dependencies. Analyzing this example will give us a good insight into the strength of this metric.

First, let's calculate staleness as exercise. We consider each stale edge separately, and generate a spanning tree with that edge. So we have the following trees:
(20, 30) with staleness of 5
(20, 31) with staleness of 3
(10, 20, 30, 31) with staleness of 4
(10, 21, 31) with staleness of 2
The total is 24 (5 x 1 + 3 x 1 + 4 x 3 + 2 x 2).
If this seems a bit awkward, consider how you would approach integration if there were several toxic dependencies which would break downstream builds, and yet you still wanted to integrate as much as possible. If latest version of 20 broke in integration with 30, or 10's latest version broke 31, you would want to integrate as much as possible before things broke. So consider this partially integrated graph, where breaking changes above prevented further integration.

Let's look at how the edge between 20 and 30 got to be 5 versions behind. At first, we'd integrate as much as possible of 20 into 30 only to find out that the latest does not work. So at that point, the 20-30 edge would be one version behind. Then we might try and integrate 10 into 20 all the way, producing 4 more versions of 20, none of which could be integrated into 30, leaving the 20-30 edge 5 versions behind again. At that point, 20-31 would be 7 versions behind, but only latest version of 10 being toxic to 31, the integration could proceed all the way to the last-but-one version of 20, leaving the edge 20-31 one version behind. The same process would take place around the 10-21-31 tree.
Note that we did quite a bit of integration, and actually exposed backwards incompatible breaks in our code. We'd expect the integration metric to go down significantly, and indeed when we calculate it, we see that it is down from 24 only to 7.